



By: Octavio Horacio Iacoponelli, Enrique Molina-Giménez (Universitat Rovira I Virgili)
As information volumes grow at unprecedented rates, the need for smarter, faster, and more versatile systems becomes critical. Collecting vast amounts of data is not enough — we need to ensure we make the most of it.
This is where Dataplug comes into play. Originally designed for unstructured scientific data, Dataplug is a client-side Python framework built to enable efficient, read-only, cloud-aware partitioning of large datasets stored in Object Storage (OS).
Dataplug’s strong scientific foundation, flexibility and design made it the ideal platform for extending it into the field of astronomy. A new astronomy-focused plugin has been specifically designed for the MeasurementSet format. This addition brings dynamic, on-the-fly partitioning to astronomical datasets stored in the cloud.
How do we — and the TASKA-C use case in particular — benefit from this new plugin?
To answer this question, let’s break down how the pipeline had operated until now:
As previously explained here, the input file (MeasurementSet) needed to be divided into manageable slices that, on their own, were independent, fully functional fragments.
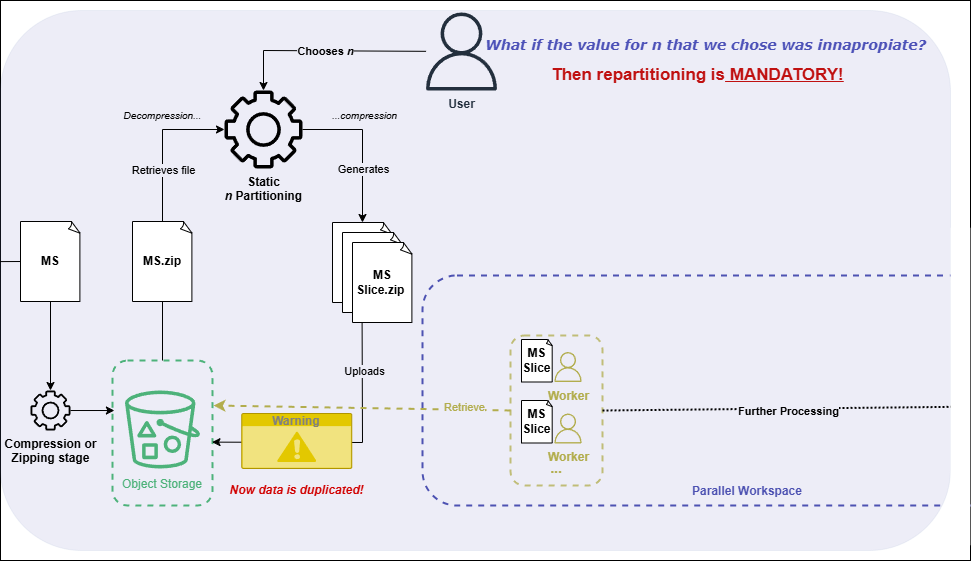
Figure 1: Previous workflow for MeasurementSet partitioning
Until now, data partitioning had been a mandatory but inefficient step. To launch a processing pipeline, the dataset had to be statically partitioned. This meant downloading the entire dataset at runtime, splitting it into fixed-size chunks, and re-uploading them to object storage. The approach not only unnecessarily duplicated data. it also locked users into a single parallelism configuration—one worker per chunk.
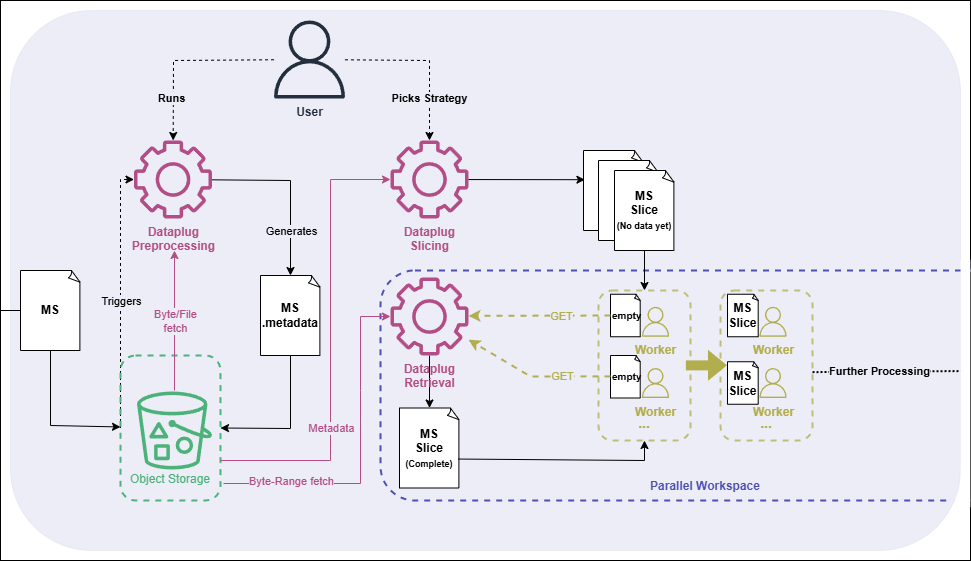
Figure 2: Current workflow for partitioning incorporating Dataplug.
Thanks to Dataplug, partitioning now works as follows:
1. We preprocess the file. The preprocessing function can take place as soon as the data is uploaded to OS. Preprocessing is a one-time operation. The dataset remains ready for later use, and its resulting metadata is stored separately. Preprocessing a previously uploaded file is also possible as the read-only operation can be done inside a worker process without downloading the entire file.
2. We then choose the number of partitions. This is a zero-cost operation, which requires no data movement. In return, we get a set of slices that can be distributed to worker processes.
3. When a worker operates on a slice, it simply calls a function, which issues byte-range requests to the OS and then reconstructs a functional MS slice.
4. Finally, the worker can proceed with the rebinning stage.
So, to answer the question, this plugin offers several benefits that can be used in the TASKA use case and beyond:
- It enables us to preprocess files as soon as they enter object storage, and to re-partition them at zero cost—something that will be especially valuable for the previously discussed smart provisioning strategies.
- It also minimizes unnecessary data transfers by avoiding full downloads or uploads. Each worker can independently fetch and reconstruct only the data it needs, which means any potential overhead from retrieval is mitigated by parallel execution.
- This astronomy plugin will soon publicly become part of Dataplug, and integrated with Lithops, enabling the smart provisioning of the use case.