



By: Universität Rovira i Virgili
The advent of serverless computing was primarily aimed at abstracting the management of computational infrastructure for developers. From that moment on, programmers could stop worrying about server configurations.
A great example of this is Lithops, a distributed computing library, which allows us to run concurrent code in the cloud with minimal configurations. While this abstraction broadly holds true, it does not entirely apply to some parameters, requiring that users still configure certain settings, which are often defined suboptimal.
Let’s take our TASKA-C astronomy use case as an example. The workflow for computing spatial images from extreme astronomical data (Measurement Sets) was parallelized by adapting the workflow to run on the Lithops framework.
Following this adaptation, several parallel workers compute the preprocessing phases before the graphical representation of the filtered data. The current workflow operation is shown in Figure 1. To date, running parallel workflows in Lithops requires the user to configure both the number of workers and the memory/CPU allocated to each one. Similarly, this is also the case with other existing parallel programming platforms.
Figure 1: Current TASKA-C workflow operation
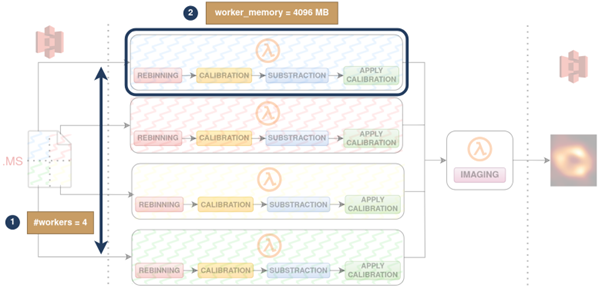
The degrees of freedom added by the possible combinations of 1)number of workers and 2) worker size, not managed by the Function-as-a-Service (FaaS) platform, distance us from the serverless experience. The user can either: 1) set acceptable parameters for execution, resulting in suboptimal experiences in both execution times and costs, or 2) spend time manually searching for a better configuration in a “trial and error” process that significantly reduces productivity.
For this reason, the TASKA-C case does not only settle for a serverless deployment. It also strive to further abstract users from configurations, achieving the ultimate serverless experience.
To this end, URV is focusing its efforts on developing a new library that precisely calculates the optimal number of workers and resource allocation for serverless workflows. While this library is motivated by the development of the TASKA-C use case, it is intended to have a general nature and be applicable to any serverless workflow, providing optimal configurations that save both time and costs. Initially, the library will apply to Lithops, but in the future, other distributed computing frameworks could also be supported.
Figure 2: Architecture of the URV serverless smart provisioner library
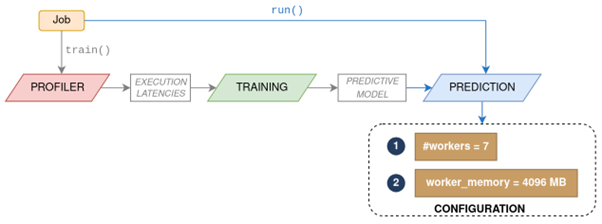
The architecture of this innovative library shows it will consist of the following modules:
- Profiler: To execute the workflow with different configurations, recording the latencies for each.
- Trainer: To train a predictive model that learns from the data on the previously obtained latencies.
- Predictor: To use the predictive model to infer the optimal configuration under which to launch the workflow.
As a result of the productive efforts of the URV partner, a first version of this serverless workflow optimizer library will soon be obtained. Applied to the TASKA-C use case, it will demonstrate its power for minimising economic costs and execution times for obtaining spatial images.
Next steps will seek to integrate these capabilities into the Lithops parallel computing project, thereby enabling Lithops to automatically determine the optimal configuration for running the job in a totally transparent way.