



By: Enrique Molina and Daniel Barcelona, Universitat Rovira i Virgili (URV)

Image copyright of SKAO
The EXTRACT project is working to bring the latest technological innovations to solve societal and scientific challenges. In the case of the TASKA (Transient Astrophysics with a Square Kilometre Array Pathfinder) use case, project partners are working to create workflows that will process extreme data so that it can be used across a variety of scientific disciplines.
In the TASKA use case, many antennas are responsible for collecting a large amount of data of variable volume and at variable speed (extreme data) that will be subsequently processed to generate high-resolution images of the cosmos. To help generate these high-resolution images, the EXTRACT project is pursuing technical synergies that will help create and improve the workflows used in the TASKA use case by integrating the latest cloud technologies in data processing parallelisation.
The data processing to arrive at these images requires several successive steps to prepare and then analyse the data collected by antennas in the Measurement Set (MS) format. These steps are: 1. rebinning, 2. calibration, 3. subtraction, 4. applying calibration, and 5. imaging.

Figure 1: Example of current pipeline where antennaes collect data and generate images.
Currently, this pipeline yields poor performance since it is executed monolithically on-premises and becomes a hassle for scientists to explore these data effectively. Indeed, this process has potential for many improvements. EXTRACT partner, the Universitat Rovira i Virgili (URV) is currently working on two notable improvements (inter-job parallelisation and intra-job parallelisation) to increase the performance of data processing in the TASKA use case.
Using serverless technologies represents one ideal scenario for executing this pipeline. These technologies offer many advantages by allowing for high scalability, a pay-as-you-go model, and abstraction of the underlying infrastructure. URV is using a Function-as-a-Service approach and its corresponding parallelisation (specifically the Lithops framework as the best identified tool available for this task) to improve the current TASKA pipeline
The first improvement that URV is employing is inter-job parallelisation. In this case, ‘job’ is understood as an instance of this process that takes a set of MS files and generates one of the desired images. By running several jobs concurrently on different sets of functions, we already parallelise the execution of this process and create a pipeline for the creation of images, which yields performance improvements.
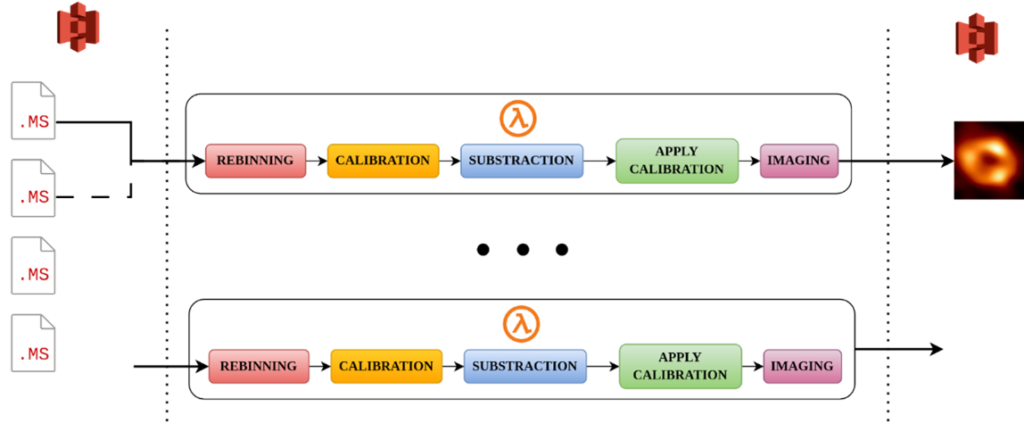
Figure 2: The TASKA use case pipeline showing inter-job parallelisation
By analysing the internals of the process it is also possible to apply intra-job parallelisation. This means parallelising different steps within the generation of the same image. This is possible for 4 of the 5 steps. It is not possible for the last step, the imaging. It is possible to split each step into multiple workers, with each taking a part of the original input dataset MS. Workers will consume partitions of the data to perform processing cooperatively. This parallelises a large part of the workload within a job and yields further performance improvements.
Performance improves even more when these two types of parallelism are combined.
Combining both parallelisation strategies can result it the fast processing of multiple datasets and a continuous generation of astronomical images that can cope with the requirements of scientists who need to analyse these images in a timely manner.
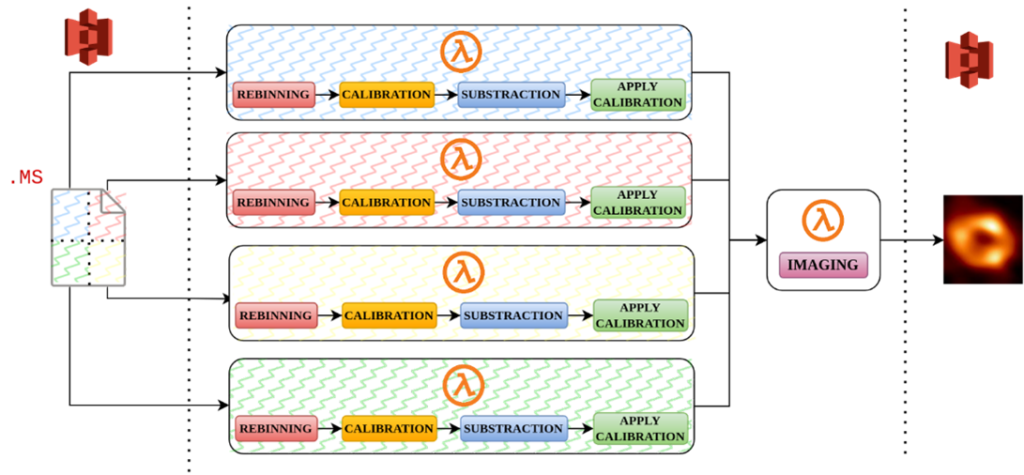
Figure 3: The TASKA use case pipeline showing inter- and intra-job parallelisation
The parallelisation of the TASKA workflow will allow it to behave elastically in the face of the variability of the extreme data that feeds it. However, there are still challenges to solve in such a complex and demanding task.
The URV team will continue with l’Observatoire de Paris for further improvements on the TASKA use case. Specifically, they will examine a novel way to ingest data efficiently. The success of this research will contribute to a better data staging solution for the EXTRACT platform, which will help reduce data processing latency with more effective resource utilisation.