



By: Mathema
Emergency situations, such as earthquakes, fires, and floods, are a critical concern for emergency services in urban areas and for urban planning. Efficient evacuation plans are increasingly important. The EXTRACT project aims to address the need for better emergency planning and crisis response by leveraging its platform to validate a Personalized Evacuation Routing (PER) system to guide citizens to safety in case of an emergency in real-time.

The PER system is being designed and tested in Venice, Italy. The city’s peculiar characteristics, specifically its geography of 118 small islands connected by over 400 bridges and the overcrowding it often faced from tourists who are unfamiliar with the city, make this case especially challeging and pertinent for crisis management. The PER system will leverage the EXTRACT platform to create a data-mining workflow that includes precise positioning, AI advanced techniques and an Urban Digital Twin that also relies on an Internet of Things (IoT) sensors ecosystem.
Implementing the PER system and creating a Multi-Agent Reinforcement Learning (MARL) model requires a preliminary phase that simulates the possible movements of people in an emergency situation to properly train the model.
To be trained correctly, the model needs to be able to evaluate its decisions “in the real world” by generating and evaluating correct and incorrect options to test the effectiveness of each path.
While in a real situation the data will be exchanged between the UDT and the MARL model, in the training phase, the simulator (SIM) plays a decisive and irreplaceable role. It takes care of exploiting the data from the UDT (roads, traffic data, reported inconveniences, physical position of the people) and from the MARL model (indications on the movements suggested for individual people) to simulate people’s movements, in the most faithful way possible compared to the real world.
A true-to-life simulator offers a safe and controlled platform for testing learning strategies in different situations, also those not reproducible in real life (e.g., after an explosion or a fire) . Furthermore, an accurate simulator can incorporate a wide range of environmental and behavioral variables, allowing learning algorithms to address a variety of real-world and complex challenges.
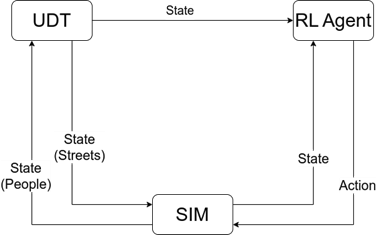
Figure 1: MARL training regime
Starting from the initial positions derived from the UDT, the MARL systematically proceeds to generate and evaluate a repertoire of potential actions, aimed at facilitating the optimal evacuation of people. After each single action generated by the MARL, the simulation component comes into play. It proceeds by carrying out the proposed actions. Starting from individuals’ initial coordinates and the prescribed actions, the simulator is tasked with orchestrating the movement of each user, in accordance with the prescribed instructions.
The movement and behavior of each user follows well-defined rules:
- Speed range. Each person moves at a variable speed, but within the range considered “normal” for a human being to walk. For simplicity, cases of people with abnormal motor skills (very fast or very slow) have been excluded.
- Direction. Each person follows the indications obtained from MARL, without making personal decisions that would lead them to move away from the destination originally identified by reinforcement learning
- Erratic movements. In this phase, erratic movements (small changes in direction which, while maintaining the final destination proposed by the MARL, affects the total time to reach the destination) are reduced to a minimum to focus attention on the correct execution of the route suggested by MARL
In the context of each iteration of MARL, the simulator is responsible for orchestrating the movement of users, using a unit time space of one second. In accordance with the specific peculiarities of each individual, each user will respond promptly and uniquely to the commands provided by MARL.
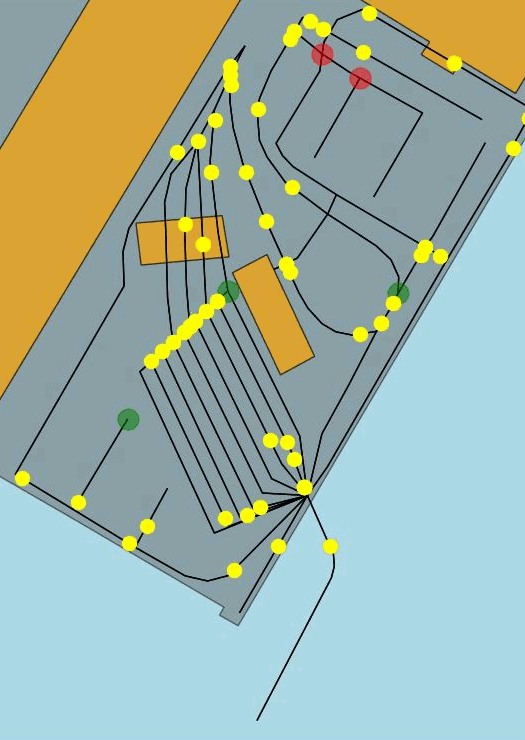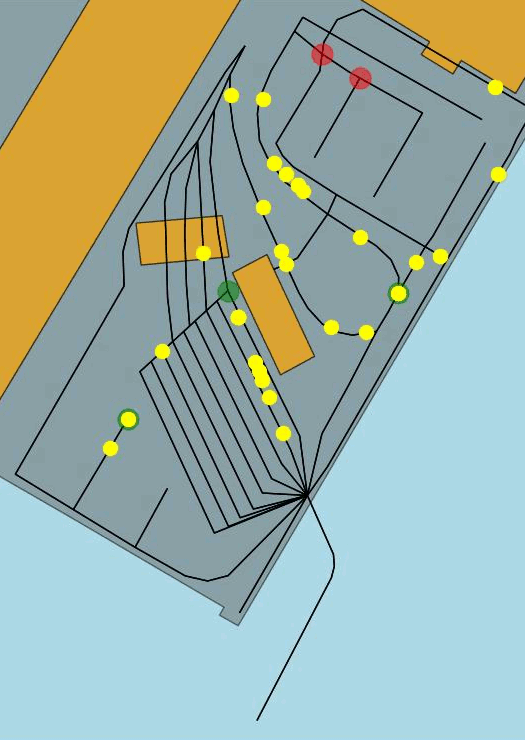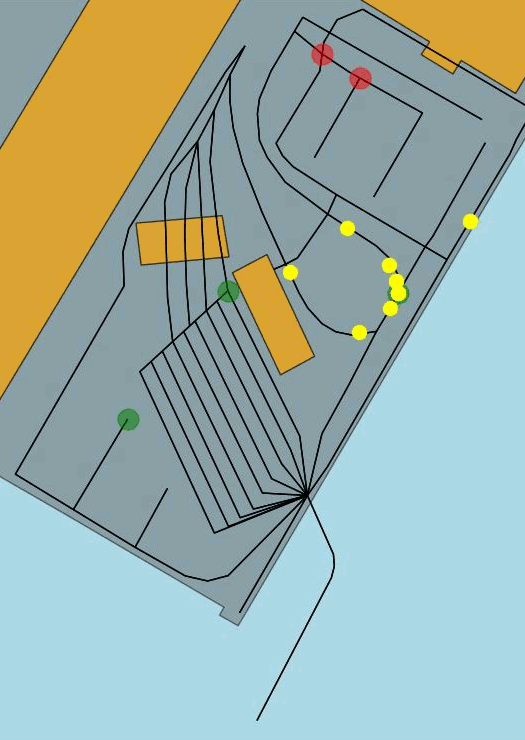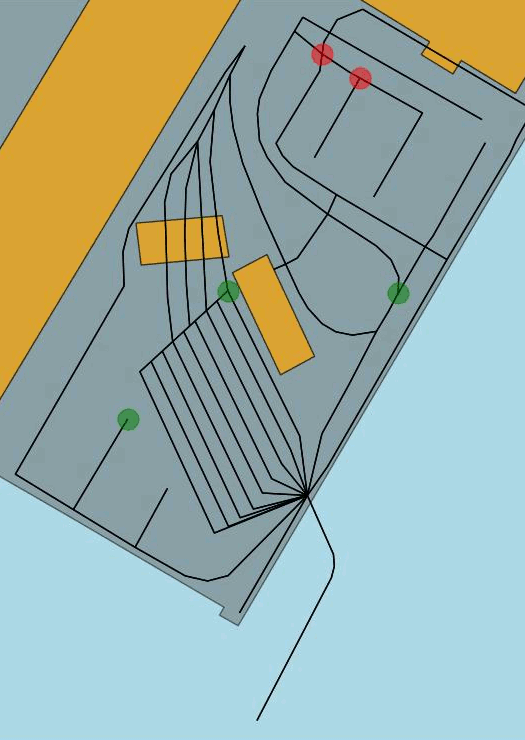
Figure 2 Example of routes proposed by the simulator
At the end of the motion processing process, the simulator will transmit the updated state of the environment, including current user locations and network dynamics, to MARL. Based on this information, the MARL will start a new iteration, perpetuating the cycle of data exchange and processing with the simulator.
The iterative cycle ends when, following the repetition of custom actions, each individual has successfully reached the designated save points on the map.