



In the TASKA use case “C”, radio telescopes are used for imaging solar activity, particularly at very low radio frequencies. At these frequencies, the Sun appears as a lower resolution disk with blurry, blobby solar ejectas. Imaging these phenomena is crucial as it helps show the direction of the propagation of solar ejections to predict whether bursts are likely to impact our system. The EXTRACT data mining workflow plays a key role in this process by identifying and storing data that is useful to a cloud data storage system.

To further enhance efficiency, the pipeline is being improved to optimize resources and to speed up the process so that there is a more efficient way of dispatching the activities as part of task C. Given the initial volume of radio data, logistic and resource management systems (including data transfer, partitioning, parallel processing, smart task scheduling, etc.) are mandatory for the data preprocessing.
Building the workflow
As part of the work in TASKA “C”, project partners are working to connect the existing software being used by the scientific community to define modular “bricks” that can be used for building an optimized workflow that can also be used for all-purpose scientific applications. This upgraded workflow will be more accessible, expanding usability from expert researchers to non-specialists and future operators who will manage the production of “science-ready” products. Currently, only experienced researchers can run scripts on computers, but by defining a high level workflow, non- specialists will be able to participate, significantly broadening the user base. This is particularly vital in preparation for the upcoming Square Kilometre Array, where accessible and efficient workflows will be essential.
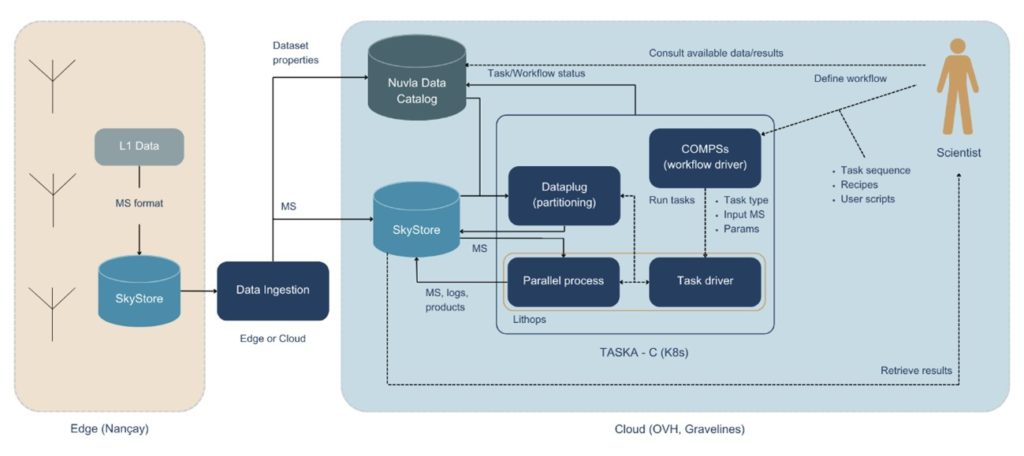
The overarching goal is to create an end-to-end workflow that non-experts can follow, allowing broader community engagement and lowering the barriers to working with this data. Additionally, speeding up the workflow will enable researchers to conduct tests much more rapidly, reducing processing times from hours to minutes. Efficient data reduction is crucial because large datasets cannot remain long on storage systems without causing significant bottlenecks. Furthermore, baseline workflows can be adapted by experts to meet their specific research needs, which is especially valuable for scientists who want to leverage radio data but cannot invest time in mastering advanced scripts or endure lengthy processing delays.
Prototype and next steps
The EXTRACT technology will simplify user access by providing a Python package for advanced users to initiate the system. Data distribution and processing will occur seamlessly in the background, enhancing user-friendliness. Non-experts, on the other hand, will be able to use predefined workflows for routine data processing “recipes.”
Following an internal Hackathon in June 2024, the first working prototype of this system was developed and tested end-to-end on a cloud computing infrastructure. The next steps involve comprehensive prototype testing and evaluation to refine the outcomes. During the Hackathon, URV and ObsParis collaborated to define key stages, options, and outputs that shape the current workflow. This resulted in a streamlined three-step process: 1) preparing the data, 2) calibrating it, and 3) generating images from the raw data.
The prototype’s modular design allows for easy adaptation and expansion, enabling users to customize scripts or add new steps as necessary. This approach ensures that the workflow remains versatile and meets the evolving needs of the scientific community.
More information about the TASKA use case can be found here.