



The TASKA “A” use case seeks to efficiently detect and model the solar activity received by the NenuFAR radiotelescope in Nançay, France. The goal is to develop an automatic data processing and identification system that will allow for real-time data processing and analysis, leveraging machine learning and deep learning within a cloud-based framework to identify and store imaging data.

Real-time solar activity detection with EXTRACT technology
Using EXTRACT’s advanced extreme data mining workflows, TASKA “A” will detect solar activity in real time, allowing for the identification and filtering of high-resolution data to retain scientifically valuable information. When no specific event is detected, dynamic spectra are recorded at a reduced rate. However, when a solar event is detected, the system automatically adapts to the optimal data rate and resolution (temporal and frequency) to capture the full spectrum of scientific details.
This task involves: i) developing the detector (model serving trained on representative data), and ii) implementing the automatic data rate switching in the data recorder.
Automation to handle massive
Solar data processing is currently a labor-intensive process requiring manual examination of raw data. With 56TB of raw data on solar activity generated per day, this method is tedious and inefficient. As part of the EXTRACT project, a new algorithm has been developed to analyse and filter incoming data in real time and store it.
EXTRACT technology continuously analyses the flow of data from pixels focused on the sun. The code is currently being optimized and the architecture for this system has been defined to introduce the environment that the activity will be run on. This architecture includes logic for event detection and ensures that sufficient computational resources are allocated for real-time processing.
Data Reduction and Accessibility
The data-mining workflow processes raw signals from the radio antennas, ultimately producing 1 to 2 petabytes of reduced data per year—a 100-fold reduction compared to the raw data. This refined data, comprising transient signals and selectively recorded samples, will be stored in a public data lake accessible to the global astronomy community.
TASKA on the Compute Continuum
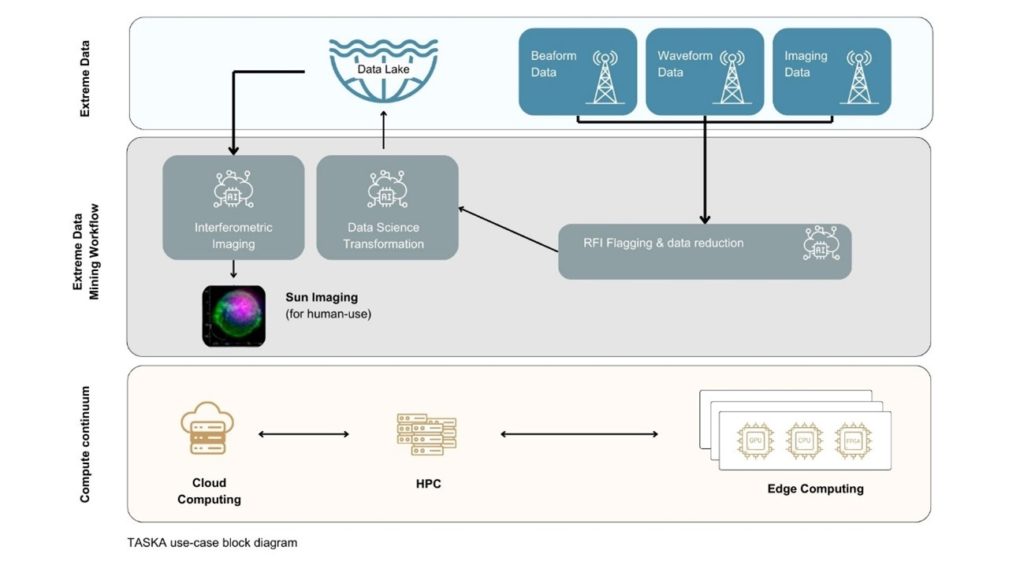
TASKA will be deployed on a heterogeneous compute continuum, which includes:
- Edge Devices: Located near the radio antennas, equipped with FPGA, GPU, and many-core accelerators.
- Storage Infrastructure: A dedicated 2PB space for local data handling, and a 7 PB cloud storage for long term data accessibility.
- HPC and Cloud Resources: Integrated within the NenuFAR Data Center.
The project is also working to incorporate the EXTRACT continuum infrastructure into the European Open Science Cloud, thereby supporting a wide array of scientific endeavors across the EU.
More information about the TASKA use case can be found here.