




Figure 1: AI-generated example of possible Personal Evacuation Routing system running on a smart phone
By: Erez Hadad and Yosef Moatti, IBM Research – Israel
The EXTRACT project features use cases that harness complex technology to provide value in real-world scenarios. One of these use cases is Personal Evacuation Routing (PER) system, which takes place in the city of Venice, Italy. The objective of this use case is to help people evacuate to safety during disasters, such as flood, fire or earthquake by using the EXTRACT system. The PER use case will seek to create a means for individuals carrying a device – typically a smartphone – to communicate with the EXTRACT system and receive instructions on where to find safety from the hazard, all within a designated time-limit.

Figure 2: AI-generated image of a busy Venice street during a crisis
A machine-learning (ML) model recommends where each individual should go in case of a disaster, taking into account the person’s characteristics and capabilities (age, disability, etc) and the limited capacity and labyrinthian streets and alleys of ancient Venice. To allow people’s devices to access this model, it needs to be served, i.e., be available as a remote service.
Such a model needs to be accessed by many devices over a short period of time and to respond in a timely manner. Thus, a naïve deployment of one simple server is likely not enough – the deployment needs to span multiple concurrent instances and aggregate many hardware resources distributed over many machines (CPU or GPU, memory, storage, network). The deployment also needs to support a simple management abstraction through which new versions of the model can be easily deployed (despite the many instances of model deployment), and can incorporate security policies, privacy, and additional aspects.
Enter Kubernetes (K8s)
K8s is the modern software stack for aggregating hardware in a distributed cluster and allocating it in favor of containerized applications and/or services. It offers centralized configuration-based management in a single pane of glass for the whole cluster, while maintaining additional policies such as security and privacy.
The K8s ecosystem is vast and covers many different application domains, and it tries to establish standard or common solutions in them. One of these domains is model serving, and the mainstream K8s solution for it is called KServe. At its core, KServe defines a protocol and implementation for serving models that is independent of any particular ML platform.
The EXTRACT project aims to further leverage KServe in its more sophisticated mode – serverless KServe. In this mode, each deployed model is automatically scaled out or in to meet a certain performance goal, such as response latency, processing throughput, etc. Deploying KServe in this mode allows the efficient utilization of hardware that matches the specific demand, balancing performance with costs such as energy and infrastructure.
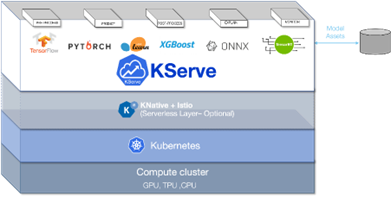
Figure 3: Overview of a deployment of serverless KServe on top of a K8s cluster
As part of the ongoing EXTRACT work, IBM Research – Israel has begun engaging with Open Data Hub (ODH), which is a popular open-source community for ML operations based on OpenShift[1] (a distribution of Kubernetes). In this context, we successfully completed our first contribution to the community’s github repository in December 2023, receiving thanks from the reviewers. The contribution fixed some issues for setting up a model service (“InferenceService”) on top of KServe and touched both code, configuration and documentation. We look forward to continuing our fruitful collaboration with this important community and reflecting its results in EXTRACT.
[1] While RedHat OpenShift is proprietary software, there is an open-source version of it you can try – OKD