



The EXTRACT project tests its technology on the TASKA and PER use cases that make use of the entire compute continuum (edge, cloud, and High-Performance Computing (HPC) resources). Workflows orchestration is a key project activity that ensures that tasks are executed where they are more suited, taking into account aspects like data location, the capabilities of the different compute resources, and the particular requirements of each task.
Within the framework of the EXTRACT project, the Barcelona Supercomputing Center is using COMPSs (Comp Superscalar) as the parallel computing tool for handling orchestration. It is great at parallelizing and distributing tasks over the available resources based on predefined rules and objectives. It also adapts on-the-go depending on the application’s needs and the current state of the infrastructure, which is why it works well for our flexible compute continuum setup.
The challenge posed by our use cases stems from their different infrastructures and the variety of workloads. For instance, some tasks need to be processed quickly and are therefore better suited to edge devices, while others require more heavy-lifting and are better for HPC resources. Similarly, tasks that require a massive usage of data might be preferably executed on the cloud. This is where COMPSs comes into play. It addresses:
- Task Allocation: COMPSs looks at what resources are available and figures out where each task should go. For example, quick tasks might run on edge devices, while data-intensive ones can be sent to cloud or HPC clusters.
- Parallelism: COMPSs doesn’t just assign tasks to resources—it also breaks tasks down further to distribute parts of them across multiple resources. This speeds things up and can be done with simple annotations in the code.
- Data Locality: In distributed systems, moving data around can slow things down. COMPSs considers where the data is and tries to run tasks close to that data, which helps in reducing transfer times and therefore saving bandwidth.
In the case of the TASKA use case, three main types of tasks need to be executed to generate an image out of the datasets: rebinning (a process consisting of splitting up datasets into smaller and more manageable chunks), calibration, and finally imaging.
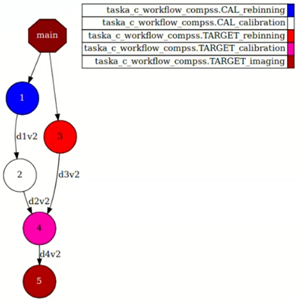
Figure 1: Sample Workflow Description of TASKA Use Case with COMPSs
The rebinning and calibration tasks might need to be executed several times before they are ready for the imaging task, creating both task- and data dependencies. Figure 1 shows a graph where each number represents a task that can be run on a different compute node. For example, tasks 1 and 2 need to run sequentially one after the other, but task 3 can be processed in parallel with them on a different node or CPU. This kind of parallelism helps us use different resources at the same time, improving efficiency of all the resources we count on and avoiding bottlenecks, improving the execution time significantly. For larger applications or those that count on many more tasks, the level of parallelism and the resources used greatly increases, making the usage of COMPSs crucial for meeting stringent deadlines.
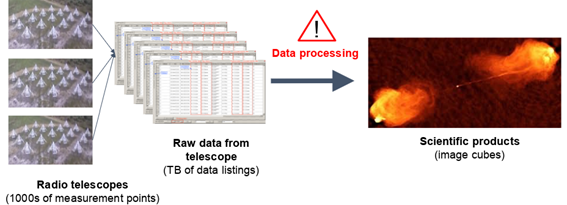
Figure 2: TASKA Rebinning, Calibration and Imaging Steps.
The logic behind the orchestration decisions made by COMPSs lies in its scheduler. We are currently using a scheduler that gives high priority to data locality for its decisions, although we are working towards a machine learning based scheduler which will take many more aspects into account and will be able to learn from the entire compute continuum environment to make more informed decisions.