




EXTRACT coordinator Eduardo Quiñones from the Barcelona Supercomputing Center was invited to speak at the 28th Ada-Europe International Conference on Reliable Software Technologoies (AEiC 2024), which took place 11-14 June in Barcelona. His talk took place on 12 June 2024 and was entitled “The Compute Continuum: An Efficient Use of Edge-to-Cloud Computing Resources”.
A key aspect of his talk focused on transforming data into “real-time” knowledge by developing, deploying and effieciently executing data-analytics workflows on highly heterogeneous computing/communication resources.
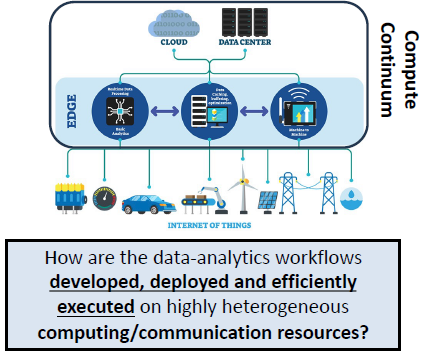
The presentation identified three key challenges to deploying workflows on the compute continuum: 1) optimizing current data infrastructures and AI & Big-data frameworks to jointly address data processes and analytics methods, 2) developing orchestration techniques to select the most approriate set of computing resources, and 3) increasing the interoperability between the most common programming practices and execution models used across the compute continuum, i.e., HPC, edge and cloud computing resources to effectively address the diverse characterstics of data.
Developing workflows on the compute continuum
The proposed three steps for developing workflows on the compute continuum:
- Exploit the parallel performance capabilities of the (different) processor architectures
- Efficiently distribute the data-analytics workflow across the compute continuum
- Guarantee functional correctness and the non-functional requirements
Eduardo introduced diferent parallel programming models and provided insights into OpenMP, COMPSs and orchestration activities.
The presentation concluded by explaining that the compute continuum provides the computing capabilities to cope with the performance requirements of complex data-analytics workflows and task-based parallel programming models allow reasoning about functional and time predictability while removing the responsibility of managing the complexity of the compute continuum from developers.