



By:SIXSQ
Efficiently managing data is one of the main challenges faced by complex computing systems, including AI. The rapid increase of Internet of Things (IoT) sensors and the vast amounts of raw data they generate have made it essential to effectively store and retrieve this information. Doing so is key to unlocking their full potential and generating valuable insights.
Most AI project failures point to flawed data. It is therefore paramount for organisations to put in place a sound data processing strategy.
In the EXTRACT project, extreme data mining workflows are designed to be able to tackle this challenge on a near-real-time basis. The two use cases of the project rely on a similar architecture: a continuum is created between IoT sensors, which first generate the data, backed by edge devices, that conduct a first-level data analysis. Finally, filtered raw data is stored in edge to cloud data lakes.
These data lakes and the way they are organized are key to be able to filter, find and process data quickly and efficiently. The Nuvla.io data management feature makes this workflow possible.
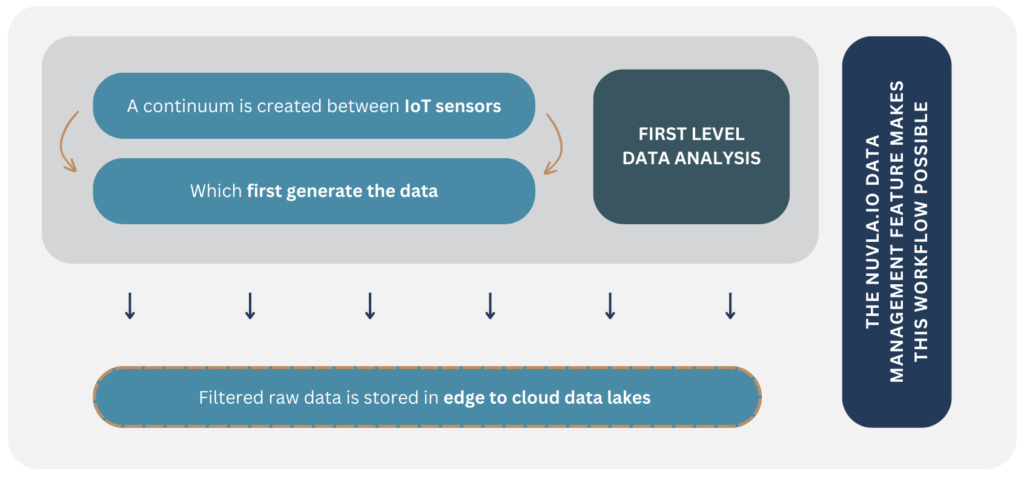
Figure 1: Visual representtion on the use of NUVLA.IO in the EXTRACT project
Nuvla.io is a Software-as-a-Service (SaaS) which provides remote management and orchestration of edge devices and applications. It is the combination of a SaaS platform, and an agent software called NuvlaEdge, deployed on every edge device to be managed through Nuvla.io.
The software offers multiple edge and cloud-related functionalities, including data management. Whenever data is created at the edge or in the cloud, at present, users are provided with programmatic tools to send data to an object store and register metadata in Nuvla.io. A new pair of data object and record are generated on Nuvla.io, with key information on the data, such as its type, location (at the edge or on the cloud), and even the link to the resources where it is stored – if given the right credentials. We are currently working on enhancing the NuvlaEdge agent to automate the delivery of data and related metadata to Nuvla.io from user-level applications, providing frictionless integration of the applications with the data lake.
While the above works for unstructured data (e.g. video, audio files), many applications produce structured data, which lend themselves well to be stored and queried as time series. This is what we call a data warehouse, as opposed to unstructured data stored in a data lake.
No user application data is stored nor accessed by Nuvla.io. Nuvla.io only holds the metadata records in a data catalogue where users can easily find and browse meta-information about the data objects they are looking for. The platform also offers Access Control List (ACL) management, to ensure that data sets are only accessible by the right authorised users.
Further, with the right credentials and user permission, Nuvla.io will soon allow users to visualise data from their data warehouse in Nuvla.io directly, simplifying data exploration and use for data scientists, AI experts and algorithms.
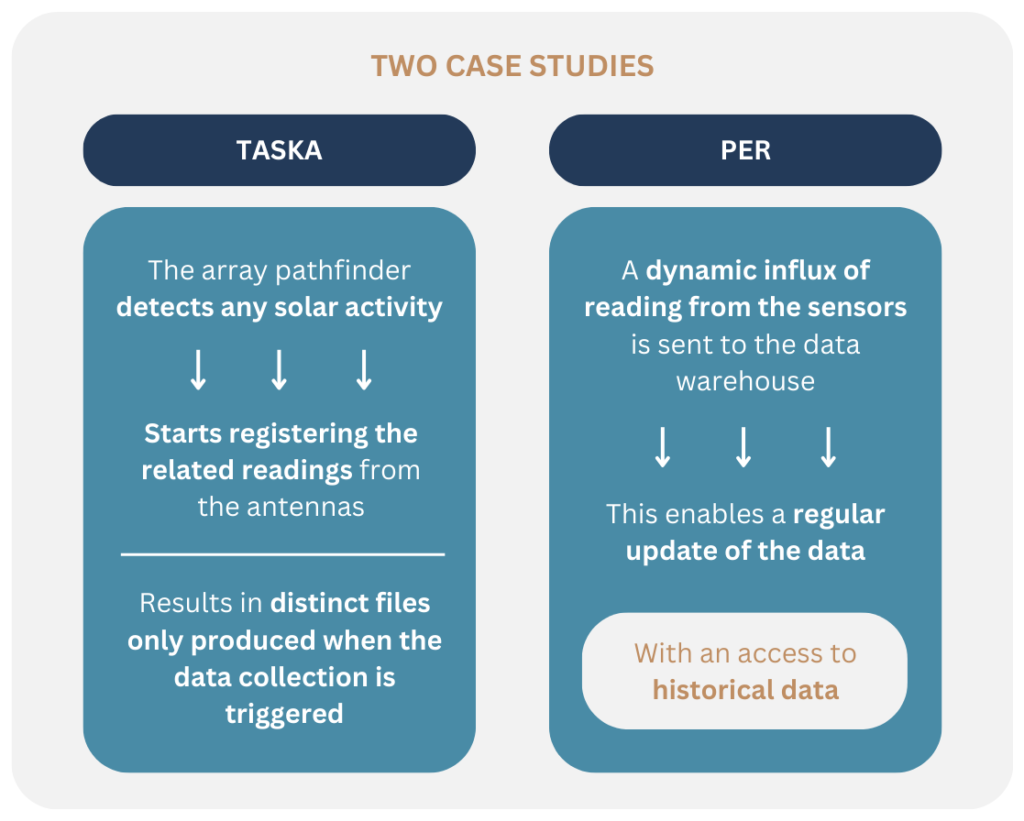
Figure 2: Visual representation of the different types of data ingestion used in the EXTRACT use cases.
In EXTRACT, the two use cases offer different types of data ingestion:
- In the transient astrophysics (TASKA) use case, the array pathfinder detects any solar activity, and starts registering the related readings from the antennas. This results in distinct files only produced when the data collection is triggered.
- In the Personalised Evacuation Route (PER) use case in Venice, a dynamic influx of reading from the sensors is sent to the data warehouse, as time series data format. This enables a regular update of the data, with an access to historical data.
Objects from the data lakes, and soon the time-series from the data warehouses, can be easily found with the Nuvla.io data management feature and retrieved to be processed and analysed by data scientists, AI experts and specific algorithms at the edge or in the cloud.